Whenever I’m asked about an interesting project completed in 42 school, the first that comes to mind is “minishell”. Minishell is the first group project in the 42 core curriculum. My teammate and I created a program Yash which stands for “yx-avery shell”. In this post, I’ll be sharing about the program, its design and what we’ve learnt during the project.
Fun fact: In school, the project is endearingly termed minihell, because as much as it’s a program we’re really proud of, the process was long and arduous.
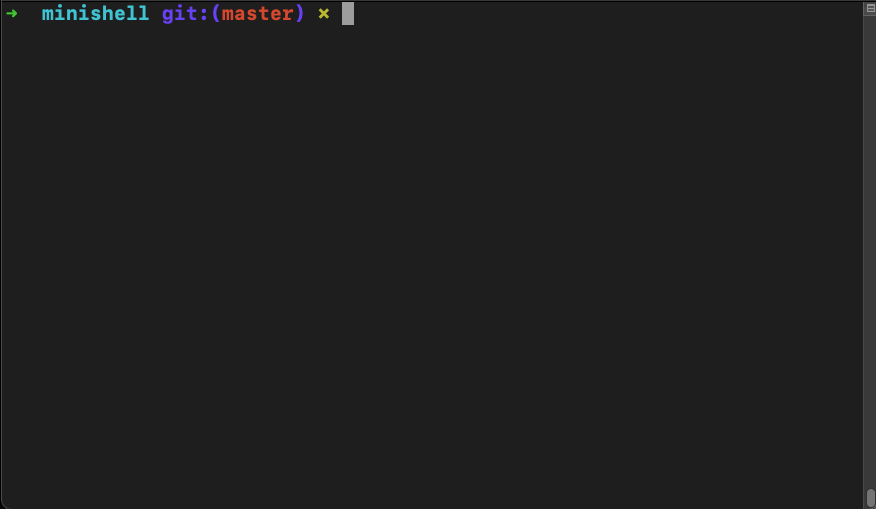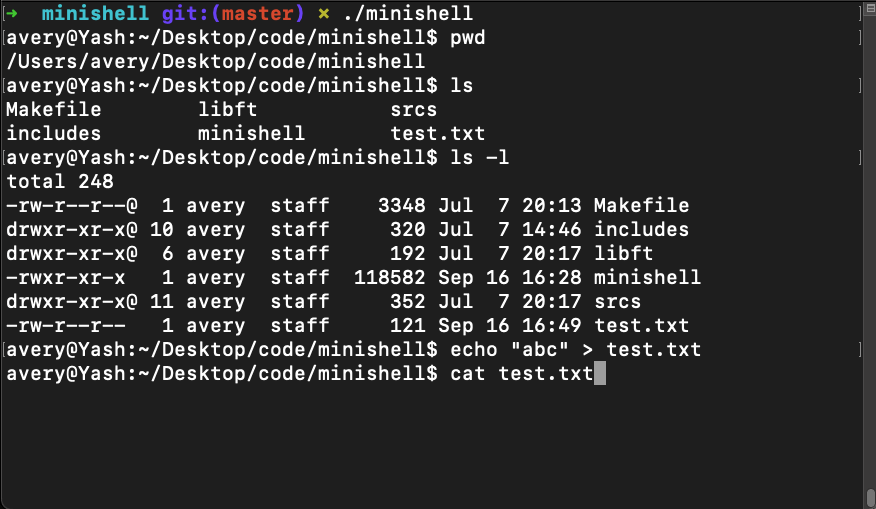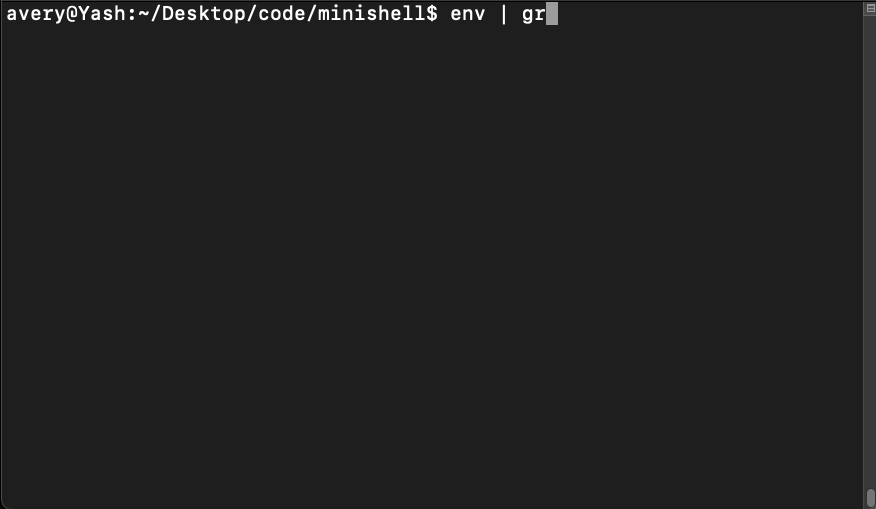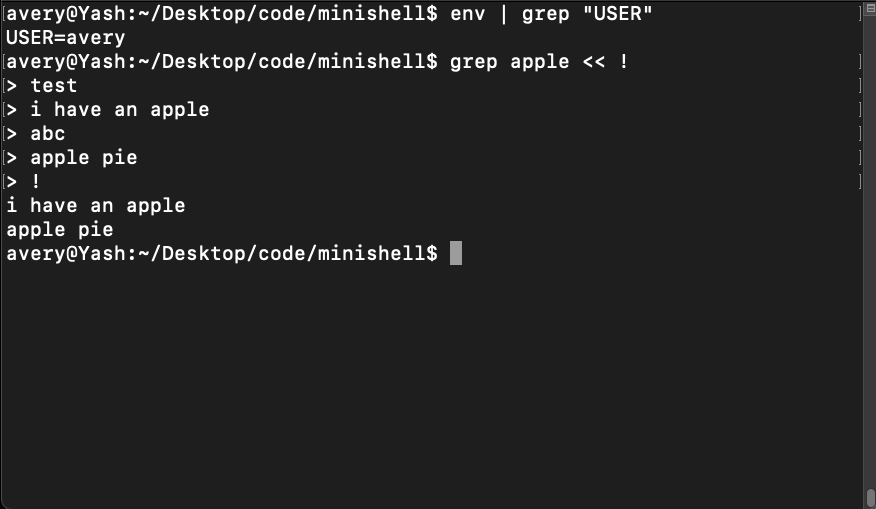
Overview of Yash
Yash is a simplified bash clone coded in C, that offers a command-line interface, input parsing, execution and more. Here’s an overview of its main features:
- Execute commands with absolute, relative and without a path
- Handle single and double quotes
- Implement pipes ( | ) to redirect in/output
- Implement redirections, including heredoc (<, >, >>, <<)
- Handle environment variables, including return code ( $? )
- Signal handling (Ctrl-C, Ctrl-\, Ctrl-D)
- Built-in commands: echo, pwd, cd, env, export, unset, exit
- && and || operators
- Parentheses for priorities
- Wildcards ( * ) for the current working directory
Program design
After some research into how bash works, we divided the program into these main components: tokenization, parsing, expansion, built-in commands and execution. This is based on a basic shell architecture as illustrated:
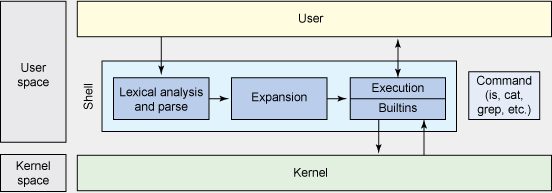
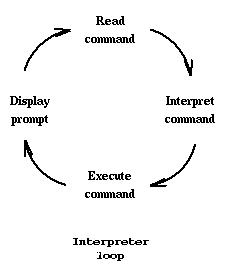
Our program follows an interpreter loop; an infinite loop that reads input, interprets the input, executes the command and waits for the next input.
Tokenization
The first step of input interpretation is lexical analysis – the process of converting text into a sequence of tokens. This allows us to identify tokens and its type, handle errors and have a way to store tokens and their order. Our tokens are stored in a doubly linked list for its dynamic size and so that nodes can be added or removed easily.

Parsing
The next step is syntax analysis, where we take our stream of tokens and organize them into a syntactic structure. This accounts for commands, operators, order precedence and redirections. It brings meaning to the raw tokens and structures them in a way that can be executed by the shell.
For parsing, we explored various techniques and opted for precedence climbing parsing – a simple and efficient method that allows us to easily manage expressions with operators such as &&, ||, |, and parenthesized sub-expressions.
Precedence climbing works by recursively breaking down expressions based on operator precedence. The key idea is that expressions are formed by atoms (individual terms or parenthesized expressions) which are connected by binary operators. The parser begins by consuming the next atom and then checks the operator following it. If the operator’s precedence is at least as high as the current minimum precedence, a recursive call is made to parse the sub-expression.
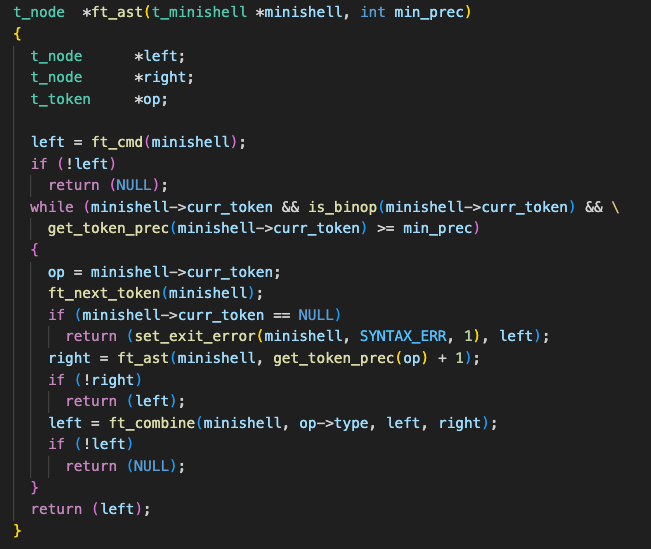
Here’s an example parsing the input “cat && ls || echo ‘abc’”
- The ft_ast function is called with the initial list of tokens and min prec of 0. The function consumes the first token, cat, which becomes the left node.
- Enters the while loop as && is a binary operator with a precedence of 0
- && is stored as the operator (op) and ft_ast is called recursively to parse the next token “ls”, which becomes the right node
- ft_combine builds the “cat && ls” subtree
- The while loop continues, as the binary operator is ||, which also has a precedence of 0
- || is stored as the operator (op) and ft_ast is called again to parse the next token echo ‘abc’, which becomes the right node for the || operator
- Finally, ft_combine builds the tree. The left node is the cat && ls subtree, and the right node is echo ‘abc’, with || as the root.
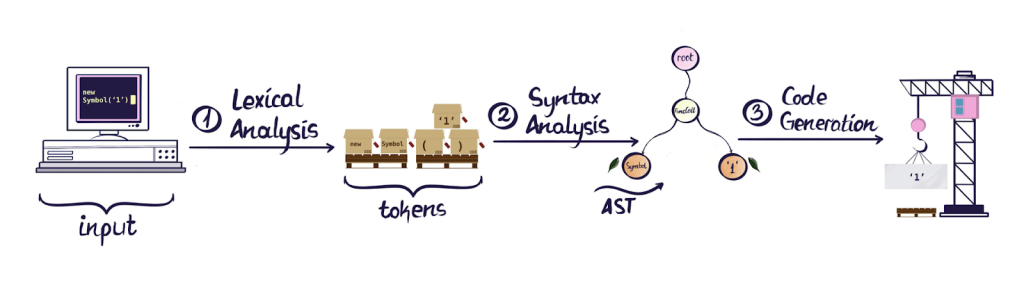
Figure from https://x.com/_lrlna
Once the tokens are parsed, they are organized into an abstract syntax tree (AST). Two commonly used structures for parsing are AST and parse tree (more on the differences here). In short, a parse tree retains all information of the input and is heavier while an AST is abstracted, focusing on parts that affect execution. We decided to use an AST because it simplifies execution and allows us to focus on the logical structure of the code. The abstraction of unnecessary details makes traversal and execution of the tree more efficient.
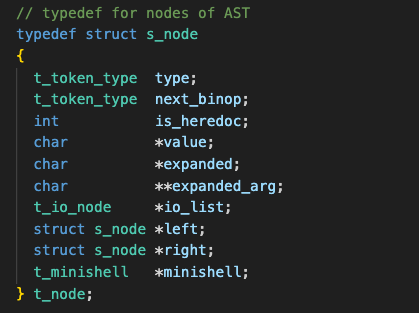
During parsing, redirections (<, <<, >, >>) are stored in a linked list called io_list, which is maintained within each AST node. This structure allows us to handle multiple chained redirection operators for each command.
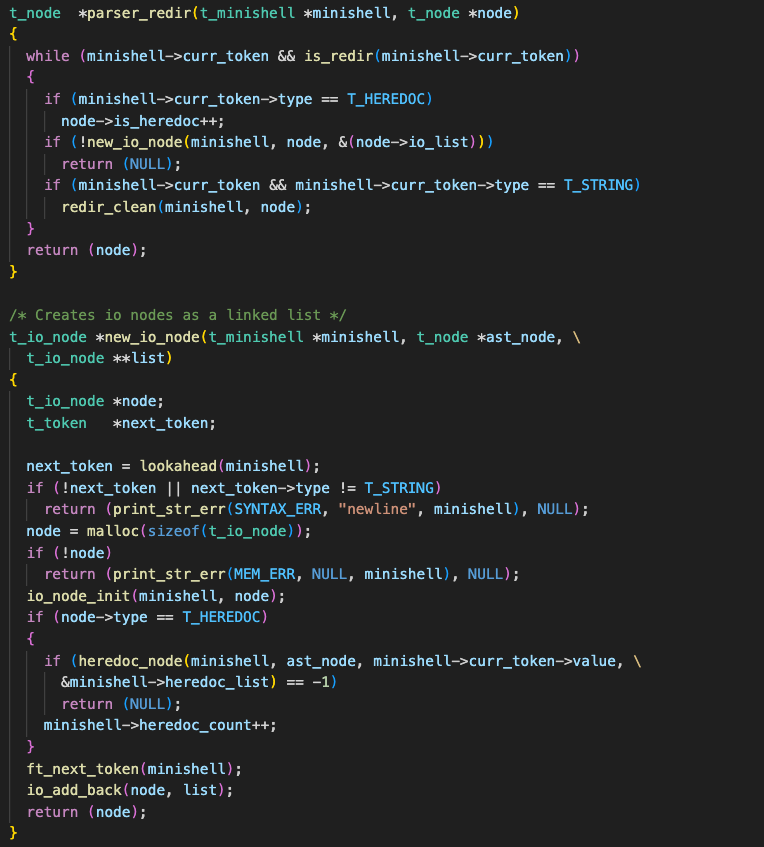
Execution
After the tokens have been parsed into an AST, the program is ready to execute commands. This is done by traversing the tree and managing processes. Each command is executed in a separate child process, allowing us to handle multiple commands using the execve system call.
One of the main challenges we encountered during execution was handling cases when testing against bash’s behavior, particularly with chained heredocs and pipes; this took several weeks of testing and restructuring to complete.
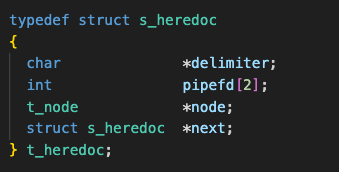
For heredocs, we needed to manage multiple delimiters, ensuring that each delimiter was found sequentially and the child process executing the command only reads the most recent input. Since heredoc input is requested before command execution, we created a separate flow to handle them by building a linked list of heredoc nodes with the following struct:
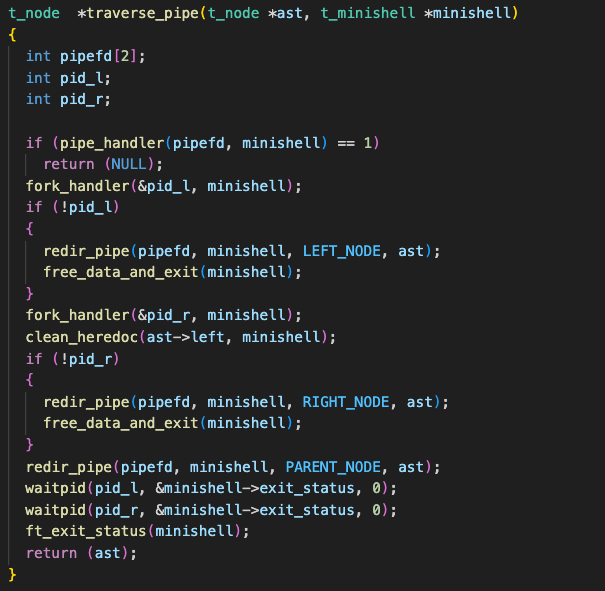
For pipes, our goal was to be able to handle concurrent execution of piped commands. An example is the command ” cat | cat | ls “; this should execute ls while waiting for cat processes’ input. To achieve this, we restructured our AST to place pipes at a higher precedence and implemented a separate pipe traversal which traverses and executes both left and right nodes of pipes simultaneously.
Collaboration
Being the first group project in 42, collaboration was a key learning experience. We started by working on different parts of the project, which required frequent communication to ensure that our structures and functions were modular and could integrate across various parts.
Personally, I found that planning and journaling were crucial to working well together, especially when there were many ongoing changes. To stay organized, we set up a trello board to track the features and bugs we’re working on, and journaled daily to reflect on our progress and set goals for the next day.
Part of our trello board
Throughout the project, we also learnt more about version control, using more git commands. One of our obstacles, unsurprisingly, was merge conflicts. Over time, we learnt how to handle these more effectively through branching, merging workflows and writing better documentation and commit messages.
Finally, one of the highlights was pair-programming. After working independently on different parts, we decided to code the execution together. We took turns as driver and observer; this helped us to learn from each other’s thought process, catch potential issues earlier and problem solve effectively.
Conclusion
Minishell was a really rewarding project, both technically and in terms of teamwork. It has deepened my understanding of operating systems, managing processes and most importantly, I had so much fun coding it with YX.
Thanks for reading! You can check out the code from my repo here.
Leave a Reply